Auth Service to Go
23 April 2024


This is one of those posts about how we migrated X from Y language to Z and all the improvements and amazing things we saw along the way. If you are triggered by this kind of post or you are a fan of Y (or some other language entirely) and are equally triggered, apologies in advance ;)
What?
So let's get started with what we did exactly. In the last couple of months we started migrating our Auth service from Node.js to Go. In order to be able to migrate this bit by bit we followed the strangler fig pattern (more on this later) and at the time of writing this document we have migrated most of the functionality already. Enough to see the benefits and start writing yet-another-I-migrated-from-x-to-y-post.
Why, Oh Why?
Several reasons, which can be summarized as:
- Performance - We are seeing lots of performance improvements which will improve end user's experience and improve scalabiity while requiring fewer resources. More on this later.
- Reliability - Using a compiled language should bring major reliability improvements compared to an interpreted language like JavaScript.
- Decoupling from Hasura - With the rewrite we decided to decouple the Auth service from Hasura, this means the Auth service will interface directly with postgres. This shouldn't have any major impact on developers, on the contrary, it will allow users to finally be able to configure whether to use camel case or snake case.
Other less technical/more subjective reasons why we decided to migrate to Go are:
- Very low entry barrier. Go is a very easy to learn programming language.
- In our personal opinion, it has the perfect balance between programming speed, ease of development and performance.
- For the aforementioned reasons, finding good backend engineers that can write Go effectively is easy.
Why not Rust?
I knew someone was going to ask. See previous paragraph :)
The strangler what?
Now that all the excuses are out of the way, let's start with the fun details. According to the wikipedia:
In programming, the strangler fig pattern or strangler pattern is an architectural pattern that involves wrapping old code [...] One use of this pattern is during software rewrites. Code can be divided into many small sections, wrapped with the strangler fig pattern, then that section of old code can be swapped out with new code before moving on to the next section. This is less risky and more incremental than swapping out the entire piece of software.
Let's see what this actually means. In PR #464 we added to the Auth service a Go process that simply proxied all requests. When a request would come in, it would forward the request to the Node.js process, nothing else:
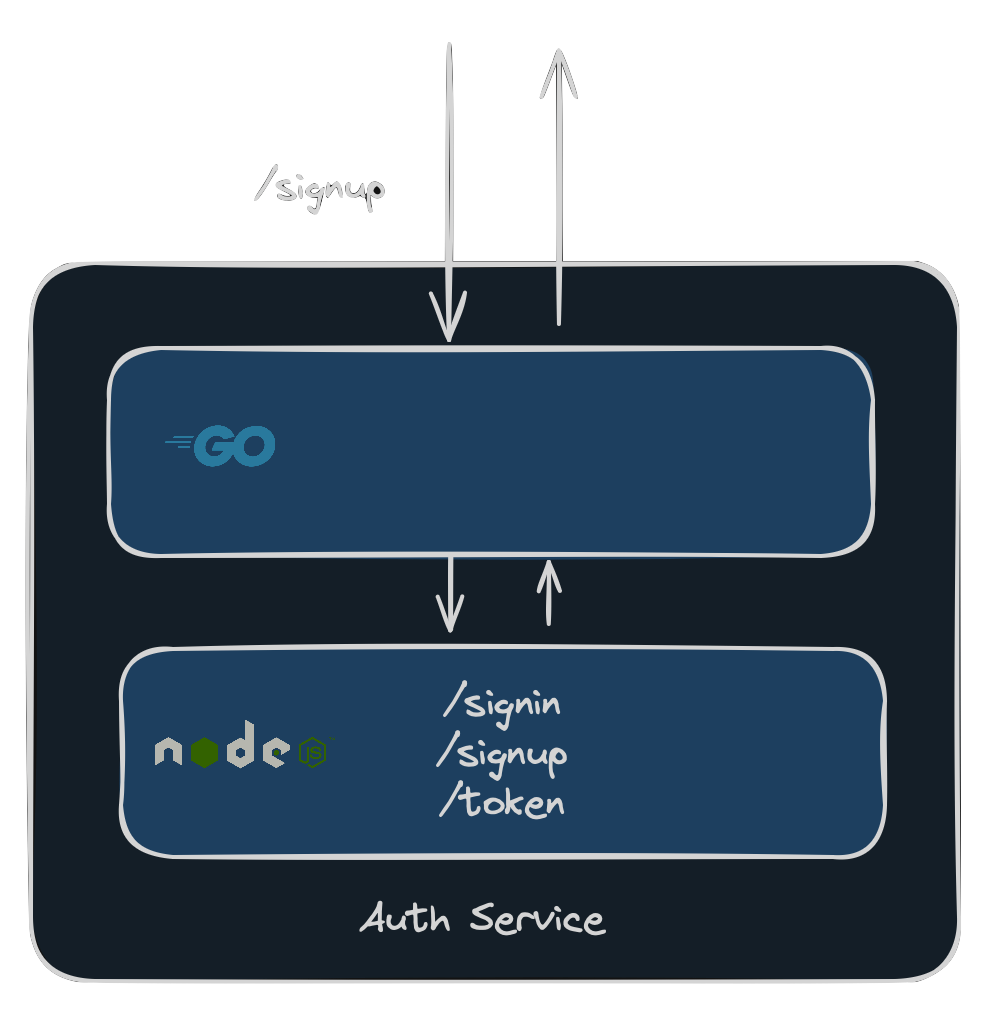 Go process proxying requests towards Node.js process
Go process proxying requests towards Node.js process
In the picture above a request to the endpoint /signup comes in, it is received by the Go process and forwarded to the Node.js one. The Go process doesn't really do anything with it.
Now that we have the Go process in place we can start migrating and serving endpoints one by one. For instance, after implementing the /signup endpoint in the Go process we can start serving it directly without any involvement from the Node.js process:
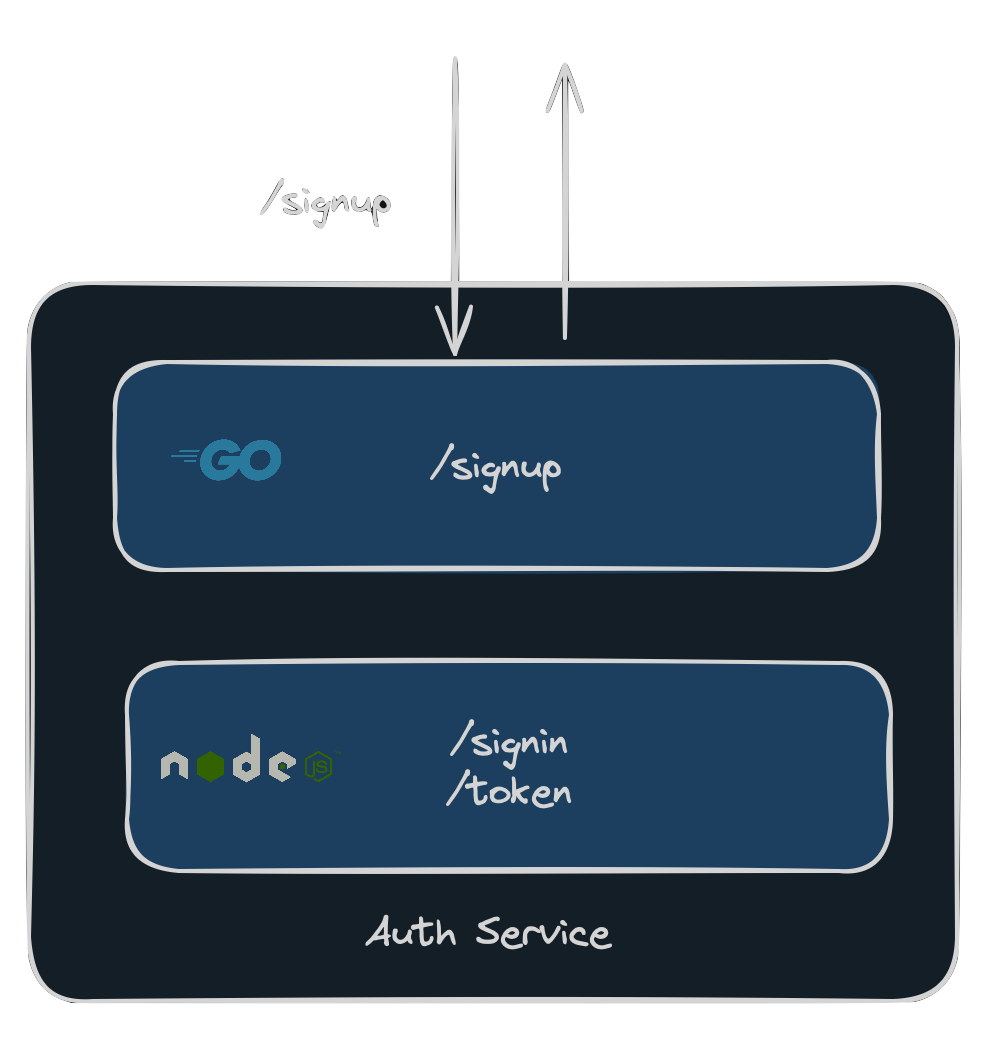 Go process serving requests
Go process serving requests
At the same time, endpoints not yet migrated will still be forwarded to the Node.js process. For instance, a request to /signin would still be proxied to the Node.js process:
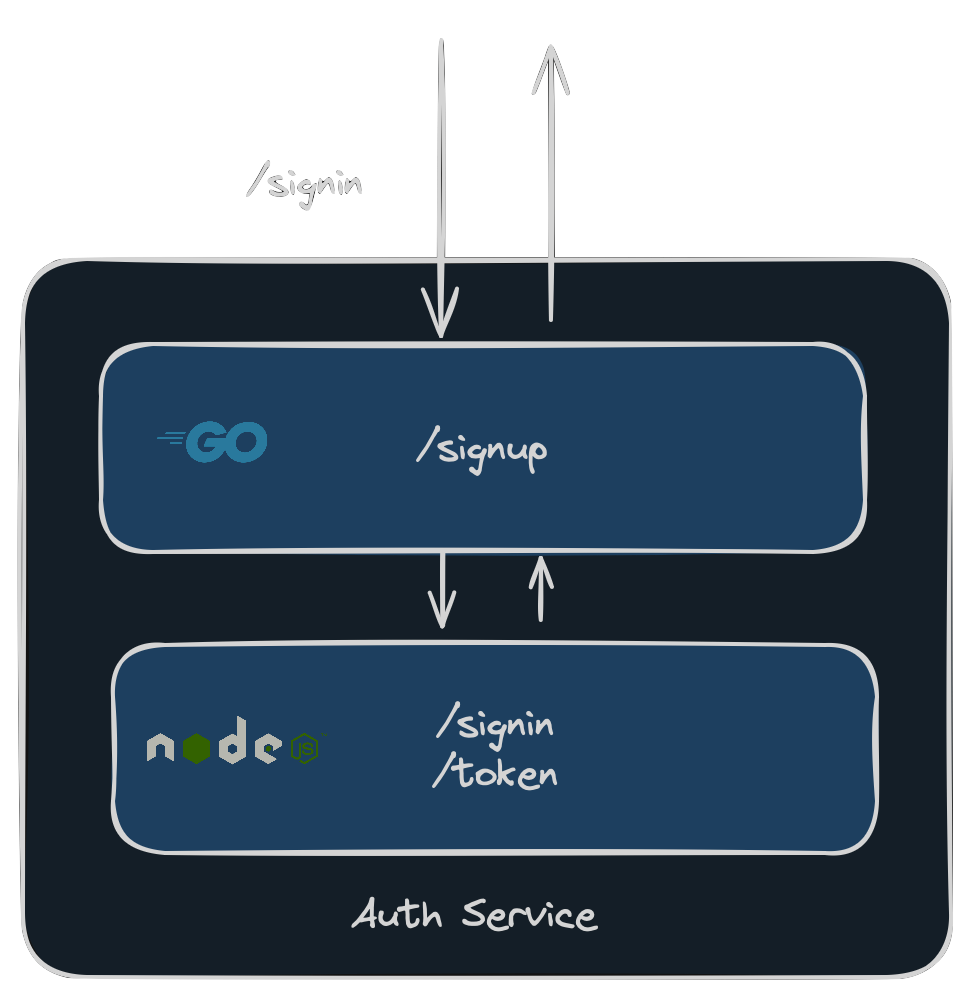 Go process proxying requests towards Node.js process
Go process proxying requests towards Node.js process
Performance Improvements
Let's start with the elephant in the room; "wouldn't adding a second process actually demand more resources?". Yes, but:
- The Go process takes ~4MB of RAM only, while the Node.js takes ~93MB so this is just a fraction of the total
- The Go process only takes a few milliCPUs to proxy the request
- As we will see below the net impact is almost negligible and even decreases memory consumption.
In order to perform the benchmarks we have set the following scenario:
- We are using a Pro project without dedicated compute. This means half a core for each service (shared).
- The project has been deployed in
eu-central-1and the tests are being executed from Stockholm, resulting in ~25ms of latency. - For each test we are going to use a different number of workers. Workers are processes that can trigger requests so if you have 100 workers that means that 100 concurrent requests will be made.
- We will test Auth v0.26.0 (Node.js) against Auth v0.29.1 (Go)
Without further ado, let's see the raw results:
| Node.js (10) | Node,js (100) | Node,js (200) | Go (10) | Go (100) | Go (200) | Go (800) | |
|---|---|---|---|---|---|---|---|
| requests completed | 557 | 1582 | 1522 | 580 | 5312 | 8943 | 23934 |
| avg | 86.31ms | 2s 690ms | 6s 510ms | 38.04ms | 35ms | 38ms | 181.4ms |
| min | 45ms | 53ms | 47ms | 27.02ms | 26ms | 26ms | 25.74ms |
| max | 487ms | 12s 100ms | 35s 32ms | 175.95ms | 251ms | 268ms | 553.93ms |
| p90 | 148.33ms | 5s 500ms | 13s 880ms | 44.41ms | 45ms | 52ms | 324.89ms |
| p95 | 256.85ms | 6s 800ms | 16s 490ms | 48.04ms | 54ms | 71ms | 356.94ms |
| peak memory | 141 | 141 | 144 | 97 | 97 | 97 | 110 |
There is a lot to unpack here, let's start by looking at the data for 10 workers. As you can see both processes completed almost the same number of requests in 60s, however, latency metrics are vastly better on the Go case. While the P95 (the latency most of your end users will experience) was ~250ms, in the Go case the latency was merely 48ms.
If we start looking at 100 and 200 workers we can see the Node.js version starts showing big bottlenecks, more interestingly you can see that with 200 workers the bottlenecks got so bad that it processed fewer requests in total that with 100 workers. On the other hand, with 100 and 200 workers the Go process handled 5312 and 8943 requests respectively. More importantly, the P90 and P95 latency metrics barely got a hit. To see what would happen we decided to test the Go process with 800 workers. Here we can see we managed to process almost 24000 requests in 60s and, while the P90 and P95 metrics go a hit, they are still within reasonable numbers given the load.
If we look at the memory usage we can also see that the Go process has better metrics than the Node.js one despite the fact that, due to the strangler pattern, the Go process actually includes the Node.js one in order to process the endpoint not migrated yet. If you consider that the Node.js process is taking 93MB when in standby, this means the Go process managed to process 24000 requests in 60s while consuming only 17MB of RAM.
Here Be Dragons
The migration should be transparent for users. The API and the SDK remains the same so what worked before should work now, and we are quite confident in our tests coverage. However, let's not forget this is a rewrite of a service with lots of features, so some edge cases not covered by the tests may suffer regressions. We ask you patience, if something arises we promise to tackle it as soon as possible. We promise it will be worth in the end.
Conclusion
While we expect a few minor bumps along the road we think migrating the Auth service from Node.js to go will bring clear benefits to everybody. We expect to see much better scale and latency metrics while decreasing resources needed.
Share this post